LLMs en la Empresa: ¿On-Premise o en la Nube? Guía práctica de seguridad, privacidad y adopción por área de negocio

Cada vez más empresas en Latinoamérica están explorando cómo integrar modelos de lenguaje (LLMs) en sus operaciones. Y cada vez que el tema llega a la mesa directiva, aparecen las mismas preguntas: ¿nuestros datos van a terminar entrenando al modelo? ¿Es más seguro instalar el modelo en nuestros propios servidores? ¿Qué opción es la correcta para cada área del negocio?
Este artículo responde esas preguntas de forma directa, desmitifica los miedos más comunes, y ofrece una guía práctica para que cada equipo pueda adoptar IA de forma responsable y segura. Además, compartimos nuestra propia experiencia: cómo construimos en SOAPros un agente de IA ya en producción que no solo responde preguntas, sino que agenda reuniones de forma autónoma conectándose a Google Calendar — sin intervención humana
1. El miedo que frena la adopción: ¿tus datos entrenan al modelo?
El temor más común que escuchamos en SOAPros cuando trabajamos con clientes en proyectos de IA es este: "Si uso ChatGPT o Claude para procesar información de mi empresa, ¿esa información va a quedar guardada y va a usarse para entrenar futuras versiones del modelo?"
Es un miedo legítimo. Y la respuesta corta es: depende de cómo uses el servicio, no del servicio en sí mismo.
¿Qué dice la política de AWS Bedrock?
AWS Bedrock —el servicio de Amazon Web Services que permite acceder a modelos como Claude (Anthropic), Llama (Meta), Mistral, Titan y otros— tiene una postura muy clara en su documentación oficial:
- AWS no usa tus prompts ni tus respuestas para entrenar modelos base. Los datos que envías a través de Bedrock no son compartidos con los proveedores de modelos (Anthropic, Meta, etc.). - Cada llamada al modelo ocurre dentro de tu entorno de AWS, con aislamiento de tenant (separación entre clientes). - Si usas funciones avanzadas como fine-tuning o continued pre-training (entrenar el modelo con tus propios datos), eso sí involucra tus datos —pero es una decisión explícita y controlada por ti, no algo que ocurre por defecto.
La diferencia clave está en distinguir entre usar la interfaz de consumidor (como chatear en Claude.ai o ChatGPT gratis) versus usar la API empresarial con un contrato de datos. En el primer caso, es posible que los datos se usen para mejoras del servicio según los términos de cada proveedor. En el segundo, los contratos suelen garantizar que no se usarán para entrenamiento.
El error más común: creer que el problema es el proveedor
Muchas empresas asumen que el riesgo está en el proveedor cloud. En realidad, el mayor riesgo suele estar en cómo los empleados usan las herramientas. Un colaborador que copia y pega contratos confidenciales en el chat público de ChatGPT está exponiendo datos, no porque AWS o Anthropic sean inseguros, sino porque se está usando la interfaz pública sin controles empresariales.
La solución no es prohibir la IA. Es implementarla correctamente.
2. Entendiendo los modelos On-Premise: la promesa y la realidad
"Descargamos el modelo y lo corremos en nuestros servidores, así nadie más tiene acceso a nuestros datos." Esta frase suena lógica y segura. Pero la realidad operativa es bastante más compleja.
¿Qué significa realmente correr un LLM on-premise?
Correr un modelo de lenguaje moderno en infraestructura propia implica:
Hardware especializado. Los modelos pequeños (7 –13 mil millones de parámetros) pueden correr en GPUs de gama media como una NVIDIA RTX 4090. Pero los modelos que realmente ofrecen capacidades útiles para empresas (70 mil millones de parámetros o más) requieren múltiples GPUs de datacenter, como las NVIDIA A100 o H100, cuyo costo unitario supera los USD 20,000.
Infraestructura complementaria. Servidores de alto rendimiento, sistemas de refrigeración adecuados, UPS, red de alta velocidad, y personal técnico especializado para mantener todo funcionando.
Modelos open-source disponibles. Las opciones más maduras hoy incluyen: - Llama 3.x (Meta): Disponible en versiones de 8, 70 y 405 mil millones de parámetros. Es la opción open-source más usada en entornos empresariales. - DeepSeek R1 / V3 (DeepSeek AI): El modelo que sacudió la industria en 2025. Rendimiento comparable a modelos de primera línea, con pesos abiertos disponibles para correr on-premise. El modelo completo requiere hardware significativo, pero existen versiones destiladas (7, 14, 32 mil millones) que corren en infraestructura más accesible. Una opción a considerar seriamente si el caso de uso requiere razonamiento complejo. - Mistral / Mixtral: Modelos europeos eficientes, con buenas capacidades en varios idiomas incluyendo español. - Falcon: Desarrollado por el Technology Innovation Institute (TII) de los Emiratos Árabes. - Qwen (Alibaba): Buen desempeño en tareas multilingües.
Nota sobre DeepSeek y privacidad:Los modelos DeepSeek en su versión cloud (deepseek.com) están sujetos a la legislación china de datos, lo que los descarta automáticamente para uso empresarial con datos sensibles. Sin embargo, al correr los pesos del modelo on-premise o en tu propio entorno de AWS, ese riesgo desaparece — el modelo es solo código, sin conexión a servidores externos.
El costo oculto más importante: el mantenimiento. Los modelos open-source no se actualizan solos. Tampoco incluyen soporte técnico. Cada actualización de seguridad, cada mejora del modelo, cada integración con nuevas herramientas, requiere trabajo interno o consultoría externa.
El stack tecnológico completo para sustituir AWS Bedrock on-premise
Aquí está el punto que más se subestima: AWS Bedrock no es solo "un modelo." Es un ecosistema completo de servicios que trabajan juntos. Para replicar lo que Bedrock ofrece out-of-the-box en un entorno on-premise, necesitas construir y mantener cada una de estas capas por tu cuenta.
Capacidad en AWS Bedrock | Equivalente on-premise | Complejidad |
|---|---|---|
Servir el modelo (inferencia) | Ollama, vLLM, llama.cpp, TGI (Text Generation Inference de HuggingFace) | Media |
API unificada para múltiples modelos | LiteLLM, OpenRouter local | Media |
Base de conocimiento / RAG | LlamaIndex + ChromaDB / Weaviate / Milvus / pgvector | Alta |
Gestión de usuarios y permisos (IAM) | Keycloak, HashiCorp Vault, LDAP/Active Directory + políticas propias | Alta |
Cifrado de datos en reposo | LUKS, VeraCrypt, configuración manual por volumen | Media |
Cifrado en tránsito | Nginx/Caddy con TLS, certificados propios (PKI interna) | Media |
Auditoría y logs (CloudTrail) | ELK Stack (Elasticsearch + Logstash + Kibana) o Grafana Loki | Alta |
Guardrails / filtros de contenido | NeMo Guardrails (NVIDIA), Llama Guard, reglas propias | Muy alta |
Monitoreo y alertas | Prometheus + Grafana | Media |
Fine-tuning del modelo | Axolotl, Unsloth, LLaMA-Factory | Muy alta |
Orquestación de flujos (Agents) | LangChain, LangGraph, Haystack (self-hosted) | Alta |
Alta disponibilidad y escalado | Kubernetes + NVIDIA GPU Operator, balanceo de carga propio | Muy alta |
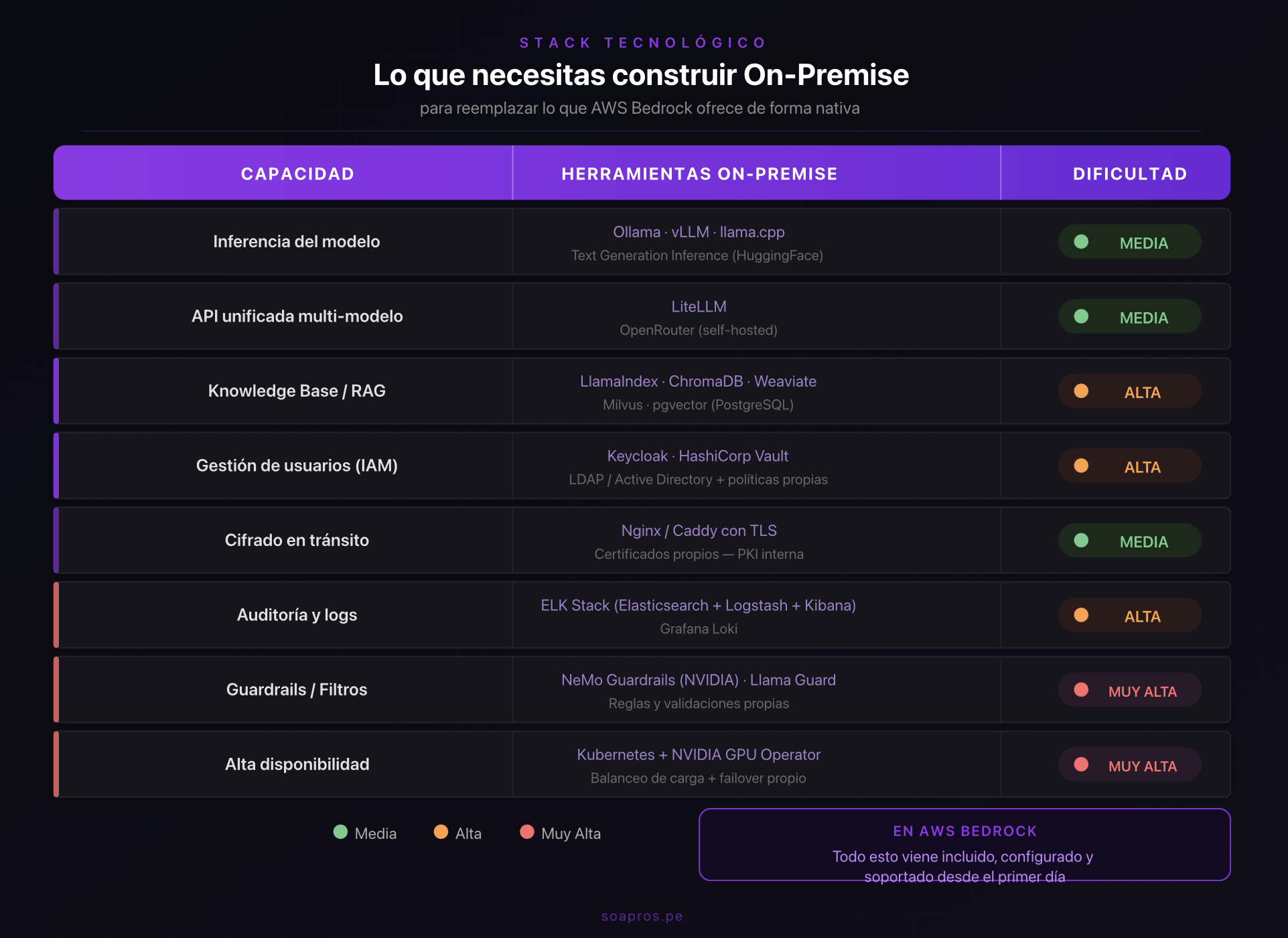
Cada capacidad que AWS Bedrock ofrece de forma nativa requiere una herramienta independiente, configuración propia y mantenimiento continuo en un entorno on-premise.
Lo que esto significa en la práctica: Un equipo de TI competente puede levantar un servidor con Ollama sirviendo Llama 3 en un fin de semana. Pero construir el equivalente completo de Bedrock —con seguridad, auditoría, alta disponibilidad, gestión de accesos y RAG— es un proyecto de varios meses, con un equipo dedicado y costos de infraestructura significativos.
No es imposible. Empresas tecnológicas grandes lo hacen. Pero para la mayoría de las organizaciones, el esfuerzo de construir y mantener ese stack desvía recursos de lo que realmente importa: usar la IA para resolver problemas de negocio.
¿Cuándo sí tiene sentido ir on-premise?
El enfoque on-premise no es necesariamente malo. Tiene sentido cuando:
- •
La organización maneja datos bajo regulaciones estrictas que prohíben el procesamiento en servicios de terceros (ciertos contratos gubernamentales, datos de defensa nacional, etc.).
- •
Ya existe infraestructura de GPU subutilizada que puede aprovecharse. El equipo técnico tiene capacidad real de mantener, actualizar y asegurar el entorno.
- •
Se necesita personalización profunda del modelo que va más allá de lo que permiten los servicios cloud.
Para la mayoría de las empresas medianas en Latinoamérica, ninguna de estas condiciones se cumple plenamente. Y eso nos lleva a la alternativa.
3. AWS Bedrock: cómo funciona su arquitectura de seguridad
AWS Bedrock no es simplemente "acceder a un modelo por internet." Es una plataforma diseñada para uso empresarial, con capas de seguridad que van mucho más allá de lo que la mayoría de las organizaciones pueden implementar on-premise con sus recursos actuales.
Los pilares de seguridad de Bedrock
Amazon VPC (Virtual Private Cloud). Puedes configurar Bedrock para que todo el tráfico entre tu aplicación y el modelo nunca salga a internet público. Las llamadas viajan a través de tu red privada en AWS, usando VPC Endpoints, lo que elimina la exposición a la internet pública.
AWS KMS (Key Management Service). Los datos que envías y recibes pueden cifrarse usando tus propias claves de cifrado, que solo tú controlas. Esto significa que ni AWS tiene acceso a tus datos en texto plano si configuras correctamente el cifrado con claves gestionadas por el cliente (CMK).
AWS IAM (Identity and Access Management). Control granular de quién puede acceder a qué modelo, desde qué aplicación, con qué permisos. Puedes restringir que el equipo de marketing solo acceda al modelo configurado para atención al cliente, mientras que el equipo de TI accede a un modelo diferente con capacidades técnicas.
AWS CloudTrail. Registro completo y auditable de cada llamada al modelo: quién lo consultó, cuándo, desde qué IP, con qué respuesta. Esto es fundamental para cumplimiento regulatorio y para detectar usos indebidos.
Amazon Bedrock Guardrails. Filtros configurables que puedes activar para bloquear ciertos temas, prevenir la exposición de información sensible (como números de documentos de identidad o datos financieros), y controlar el tipo de respuestas que el modelo puede generar.
El modelo de responsabilidad compartida
AWS opera bajo un modelo de responsabilidad compartida: AWS es responsable de la seguridad de la infraestructura (hardware, red, datacenter). Tu organización es responsable de la seguridad en la infraestructura (configuración de accesos, cifrado, políticas de uso).
Esto no es una limitación —es exactamente cómo funciona la seguridad empresarial moderna. Lo mismo aplica a tu banco: el banco protege su infraestructura, pero tú eres responsable de no compartir tu contraseña.
4. Comparativa directa: On-Premise vs. AWS Bedrock
Criterio | On-Premise | AWS Bedrock |
|---|---|---|
Control de datos | Total, en tus servidores | Alto, con VPC + KMS + IAM |
Costo inicial | Muy alto (USD 50K–500K+) | Bajo (pago por uso) |
Costo operativo | Alto (personal, energía, hardware) | Variable según uso |
Escalabilidad | Limitada por hardware | Prácticamente ilimitada |
Actualizaciones del modelo | Manual, responsabilidad propia | Automáticas, gestionadas por AWS |
Tiempo de implementación | Semanas a meses | Días |
Soporte técnico | Comunidad open-source | SLA empresarial de AWS |
Cumplimiento regulatorio | Depende de tu implementación | Certificaciones: SOC2, ISO 27001, HIPAA, GDPR, PCI DSS |
Capacidad de modelos | Limitada por GPU disponible | Modelos de última generación disponibles |
Riesgo de configuración incorrecta | Alto | Moderado (herramientas de configuración guiada) |
¿Y el enfoque híbrido?
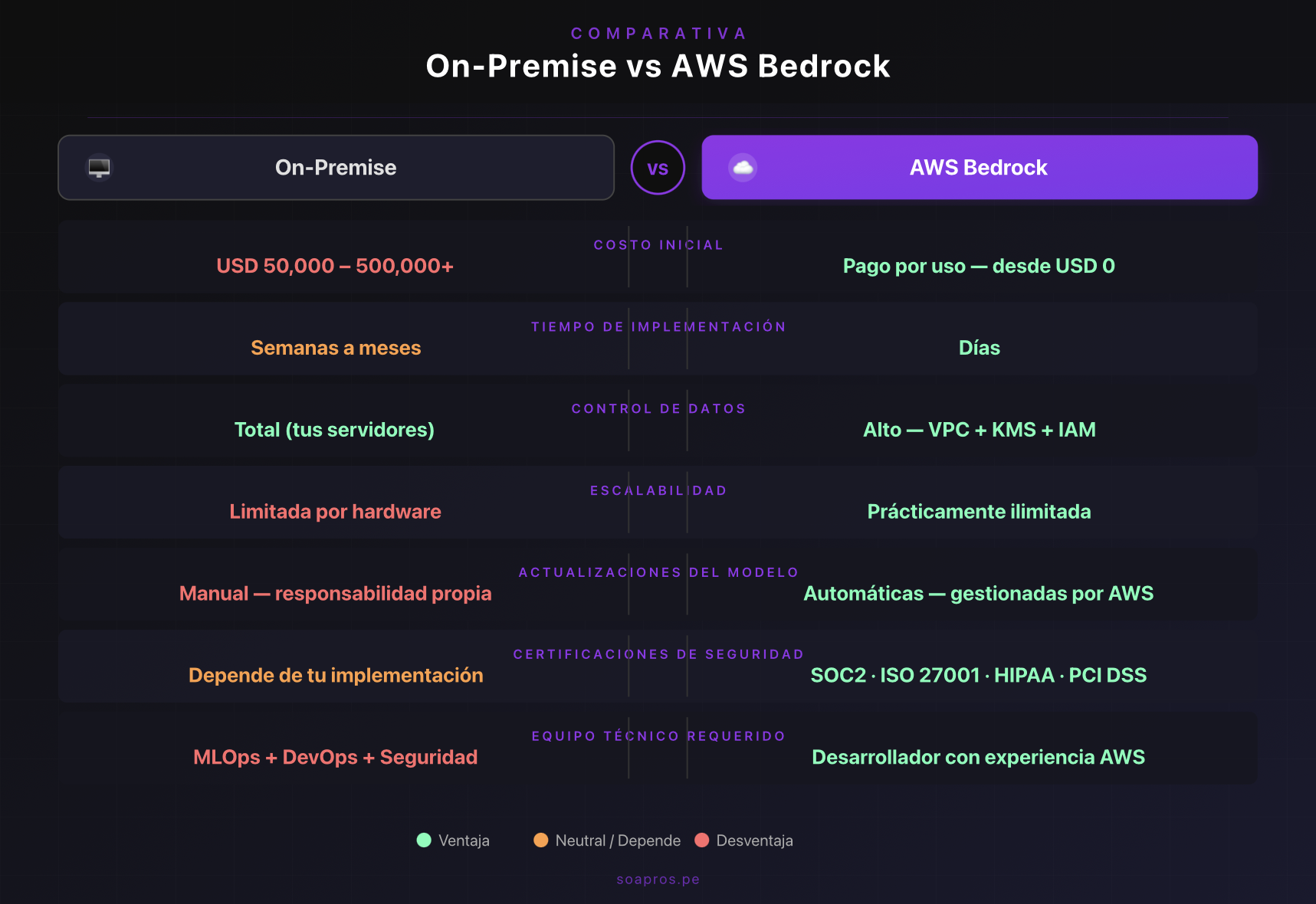
Comparativa de los criterios más relevantes para la decisión. El color refleja si cada opción representa una ventaja, posición neutral o desventaja.
Algunas organizaciones optan por una arquitectura híbrida: los datos más sensibles se procesan con un modelo on-premise de menor capacidad, mientras que tareas de menor sensibilidad usan modelos cloud de mayor potencia. Esta es una estrategia válida, aunque agrega complejidad operativa. Vale la pena considerarla cuando hay una división clara entre tipos de datos y casos de uso.
5. Seguridad y privacidad: lo que realmente importa
Antes de elegir entre on-premise o cloud, hay que entender que la seguridad no es una característica que se activa al "instalar el modelo en casa." Es una práctica continua que abarca personas, procesos y tecnología.
Cifrado: en tránsito y en reposo
Todo sistema de IA empresarial —sea on-premise o cloud— debe garantizar que los datos estén cifrados mientras viajan (TLS 1.2 o superior) y mientras están almacenados (AES-256 o equivalente). En AWS Bedrock, esto está activado por defecto. En un entorno on-premise, depende completamente de tu configuración.
Control de acceso basado en roles
No todos los empleados deberían tener acceso al mismo modelo ni a las mismas capacidades. Un asistente de ventas no necesita acceso a herramientas que pueden generar código o consultar bases de datos internas. La gestión de roles —quién puede hacer qué— es un pilar de seguridad que se suele subestimar.
Auditoría y trazabilidad
¿Puedes saber qué le preguntó un empleado al modelo ayer a las 3 PM? ¿Puedes demostrar ante una auditoría que ningún dato de un cliente fue enviado a un modelo externo sin consentimiento? Estas preguntas de trazabilidad son críticas en entornos regulados. AWS CloudTrail ofrece esta capacidad de forma nativa.
Residencia de datos y cumplimiento regulatorio
Algunas industrias y países tienen requisitos específicos sobre dónde pueden almacenarse y procesarse los datos. AWS permite seleccionar la región de AWS donde se ejecutan los modelos, lo que facilita cumplir con requisitos de residencia de datos (por ejemplo, mantener datos de ciudadanos peruanos dentro de una región específica o dentro de Latinoamérica).
El factor humano: el eslabón más débil
Ninguna tecnología, por más segura que sea, protege contra un empleado que copia información confidencial en una herramienta no autorizada. Las políticas de uso de IA, la formación del equipo y los controles técnicos de qué herramientas están permitidas son tan importantes como la arquitectura elegida.
6. Guía por área de negocio: ¿qué modelo adoptar y cómo?
Cada área de la empresa tiene necesidades distintas y distintos niveles de sensibilidad en sus datos. Aquí va una guía práctica.
Recursos Humanos
Datos que maneja: información personal de empleados, evaluaciones de desempeño, datos salariales, procesos disciplinarios.
Recomendación: AWS Bedrock con VPC privada y acceso restringido solo al equipo de RRHH. Guardrails configurados para detectar y bloquear la exposición de datos personales identificables (PII). Auditoría activada. Casos de uso recomendados: redacción de comunicados internos, resumen de políticas, asistente para preguntas frecuentes de empleados (sin acceso a datos individuales).
Señal de alerta: Si alguien en RRHH quiere usar un modelo para "analizar" fichas de empleados individuales, eso requiere una evaluación de privacidad cuidadosa antes de implementarse.
Legal y Compliance
Datos que maneja: contratos, acuerdos de confidencialidad, comunicaciones con abogados, casos en curso.
Recomendación: Esta es una de las áreas donde el on-premise podría justificarse si los contratos de la empresa prohíben el procesamiento por terceros. De lo contrario, Bedrock con cifrado de extremo a extremo y sin logging de contenido (configurable) es una opción robusta. Casos de uso: revisión de contratos, comparación de cláusulas, generación de borradores.
Señal de alerta: Nunca usar interfaces de IA de consumidor (ChatGPT público, etc.) para subir contratos confidenciales.
Finanzas y Contabilidad
Datos que maneja: estados financieros, proyecciones, datos de clientes con montos de transacciones.
Recomendación: Bedrock con acceso controlado por IAM y auditoría completa. Los modelos no deben tener acceso directo a sistemas transaccionales sin una capa de intermediación y validación humana. Casos de uso: análisis de reportes, redacción de comentarios financieros, resumen de normativas contables.
TI y Desarrollo
Datos que maneja: código fuente propietario, arquitecturas de sistemas, credenciales (si no hay buenas prácticas).
Recomendación: Bedrock es ideal para equipos de desarrollo: asistentes de código, revisión de pull requests, documentación automática. La principal precaución es asegurarse de que el código enviado al modelo no incluya secretos o credenciales embebidas (un problema de higiene de código, no del modelo en sí). Amazon CodeWhisperer —integrado con Bedrock— está diseñado específicamente para este caso.
Ventas y Marketing
Datos que maneja: datos de clientes, historial de interacciones, propuestas comerciales.
Recomendación: Es el área con más opciones y donde la IA genera más valor rápidamente. Chatbots de atención al cliente, asistentes de redacción, análisis de sentimiento de reseñas. La precaución: asegurarse de que el modelo no acceda a datos de todos los clientes al responder consultas individuales. La arquitectura de RAG (Retrieval-Augmented Generation) con control de acceso por cliente es la solución técnica adecuada.
Operaciones y Soporte
Datos que maneja: tickets de soporte, documentación técnica, procedimientos internos.
Recomendación: Área con alto potencial de automatización y bajo riesgo si se implementa correctamente. Asistentes que responden basándose en documentación interna (knowledge base) sin acceso a datos de producción son una implementación de bajo riesgo y alto retorno.
7. Recomendaciones para líderes técnicos y de negocio
Si estás evaluando cómo adoptar IA en tu organización, estos son los pasos que recomendamos desde SOAPros:
1. Antes de elegir la tecnología, mapea tus datos. ¿Qué tipos de información procesaría el modelo? ¿Hay datos regulados (salud, datos financieros, datos personales bajo GDPR o normas locales)? Esta evaluación define el nivel de control que necesitas.
2. Diferencia entre casos de uso de alto y bajo riesgo. No todos los usos de IA en tu empresa requieren el mismo nivel de protección. Empezar con casos de uso de bajo riesgo (redacción de comunicados, resumen de documentos públicos, FAQ interno) te permite aprender y construir confianza antes de abordar casos más sensibles.
3. Establece una política de uso de IA antes de lanzar herramientas. Qué herramientas están aprobadas, qué tipos de datos pueden usarse con cada una, qué está prohibido. Una página, clara, firmada por el equipo. Sin esto, el "shadow AI" —el uso no autorizado de herramientas de IA por parte de empleados— es inevitable.
4. No subestimes el TCO del on-premise. Si estás evaluando esta opción, incluye en el cálculo: hardware (inicial y de reposición cada 3–5 años), energía, personal técnico especializado, licencias de software de gestión, tiempo de integración y mantenimiento. Para la mayoría de las empresas en la región, el TCO del on-premise supera al cloud en un horizonte de 3 años.
5. Comunica la seguridad a equipos no técnicos con analogías claras. AWS Bedrock tiene más certificaciones de seguridad que la mayoría de los datacenters propios de las empresas de la región. Usar AWS no es "poner los datos en internet abierto" —es lo contrario. La misma confianza que depositamos en los bancos para guardar dinero sin necesidad de tener una bóveda propia en casa, aplica aquí.
8. Un caso real: el asistente de IA de SOAPros.pe
La teoría es útil, pero nada comunica mejor que ver una implementación concreta. Por eso compartimos nuestra propia experiencia: el asistente de IA que hoy vive en soapros.pe (https://soapros.pe).
¿Qué es y qué hace?
El asistente de SOAPros es un chatbot empresarial construido íntegramente sobre AWS, capaz de responder preguntas sobre nuestros servicios, casos de uso y tecnologías con las que trabajamos. No es un chatbot de guión fijo con respuestas predefinidas —es un asistente que entiende lenguaje natural, mantiene el contexto de la conversación y responde de forma coherente basándose en la información real de la empresa.
La primera capacidad agéntica: agendamiento autónomo
Una de las fricciones más comunes en el proceso comercial es la coordinación de reuniones. El usuario quiere hablar con alguien del equipo, pero entre correos de ida y vuelta, disponibilidades cruzadas y confirmaciones, fácilmente se pierden horas — o el interés del prospecto. Nuestro agente resuelve esto en tiempo real. Cuando un usuario dentro del chat expresa interés en agendar una reunión, el agente toma el control del flujo:
- •
Consulta la disponibilidad — el agente se conecta directamente a Google Calendar, revisa los espacios disponibles del equipo comercial y filtra según el día o franja horaria que el usuario prefiere.
- •
Presenta opciones concretas — le muestra al usuario los horarios disponibles dentro de la misma conversación, sin redireccionamientos ni formularios externos.
- •
Confirma y agenda — con la simple confirmación del usuario, el agente crea la reunión directamente en Google Calendar, enviando la invitación a ambas partes de forma automática.
Todo esto ocurre en menos de un minuto, dentro del chat, sin intervención humana. Los beneficios concretos Para el usuario:
- •
Agenda una reunión en segundos, sin salir del chat ni llenar formularios
- •
Recibe confirmación inmediata con todos los detalles
- •
Experiencia fluida que genera confianza desde el primer contacto
Para el equipo comercial:
- •
Cero tiempo dedicado a coordinación de agendas
- •
El calendario se gestiona solo, sin riesgo de doble reserva
- •
El equipo recibe prospectos ya confirmados, listos para la reunión
- •
Más tiempo para lo que importa: preparar y cerrar la conversación
Para el negocio:
- •
Reducción drástica del tiempo entre el primer contacto y la reunión agendada
- •
Menor tasa de abandono — el usuario no pierde el impulso esperando una respuesta
- •
Escalable: el agente atiende múltiples conversaciones simultáneas sin costo adicional
La arquitectura: simple, segura y escalable
El diseño sigue un principio que aplicamos a todos nuestros proyectos: usar los servicios gestionados de AWS para no reinventar la rueda en infraestructura, y enfocar el esfuerzo en la lógica de negocio.
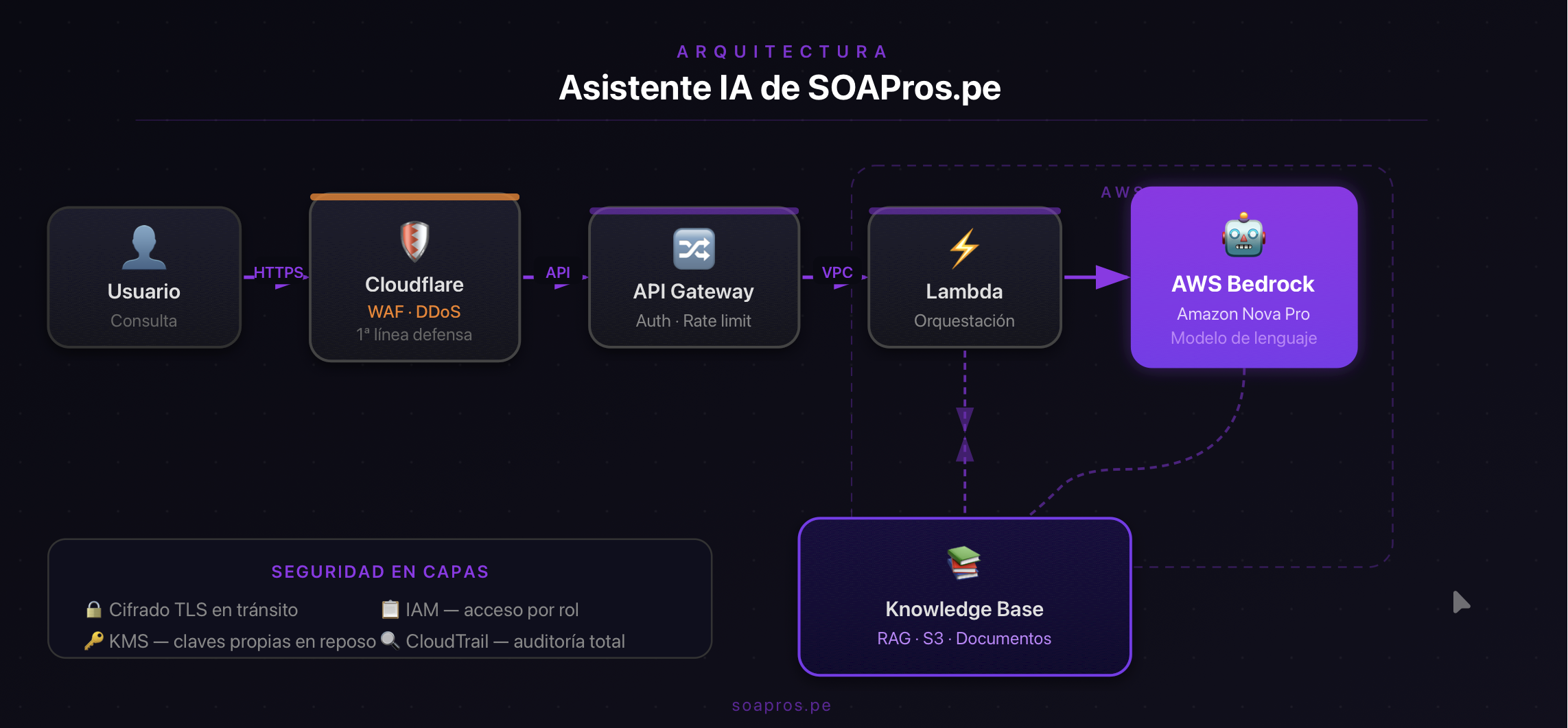
AWS Bedrock con Amazon Nova Pro es el motor de lenguaje. Elegimos Nova Pro por su excelente relación entre capacidad de razonamiento, velocidad de respuesta y costo por token —factores críticos en un chatbot de producción que atiende usuarios reales. Lo importante: ningún dato enviado al modelo sale del entorno de AWS ni se usa para reentrenar nada.
Knowledge Base con RAG sobre S3 es lo que le da al modelo conocimiento específico sobre SOAPros. En lugar de depender solo del entrenamiento general del modelo, el asistente consulta en tiempo real una base de documentos propia almacenada en S3. Esto significa que cuando actualizamos nuestra información de servicios, el asistente la refleja de inmediato —sin necesidad de reentrenar el modelo ni tocar código.
AWS Lambda + API Gateway conforman la capa de lógica y exposición. Lambda ejecuta la orquestación: recibe la pregunta del usuario, consulta la Knowledge Base, construye el contexto y llama a Bedrock. API Gateway expone el endpoint de forma segura con autenticación y control de tasa de llamadas. Todo serverless: no hay servidores que administrar, y el costo escala exactamente con el uso real.
Cloudflare como primera línea de defensa actúa antes de que cualquier request llegue a AWS. El WAF (Web Application Firewall) de Cloudflare filtra tráfico malicioso, bloquea intentos de abuso y protege contra ataques de denegación de servicio, sin agregar latencia perceptible para el usuario legítimo.
¿Por qué esta arquitectura y no on-premise?
La respuesta es directa: en el tiempo que hubiéramos dedicado a configurar y asegurar una infraestructura on-premise equivalente, ya teníamos el asistente en producción, seguro y escalable. No hay servidores GPU que aprovisionar — una sola GPU de datacenter cuesta más de USD 20,000, sin contar el servidor, la refrigeración ni el personal que lo mantiene. No hay stack de seguridad que construir desde cero. No hay preocupación por actualizaciones del modelo. Y si mañana necesitamos escalar para atender diez veces más usuarios, AWS lo maneja automáticamente sin un solo dólar adicional en hardware. El modelo de costos también cambia radicalmente: con AWS Bedrock pagamos únicamente por lo que usamos — cada consulta al modelo tiene un costo por token, medible y predecible. No hay inversión inicial, no hay costo fijo mensual de infraestructura, y no hay sorpresas. Para una empresa que está validando casos de uso de IA, ese modelo de pago por uso elimina el riesgo financiero de apostar fuerte en hardware antes de saber si la solución genera el valor esperado. En resumen: menos tiempo en infraestructura, menos capital inmovilizado, y más foco en lo que realmente importa — que el asistente resuelva problemas reales del negocio.
9. La visión agéntica: hacia dónde va esto
El agendamiento autónomo que describimos en la sección anterior es solo el comienzo. Nuestra arquitectura está diseñada desde el inicio para evolucionar — cada nueva capacidad agéntica se suma sin necesidad de rehacer la base tecnológica.
Un chatbot responde. Un agente actúa.
La diferencia es fundamental. Un chatbot tradicional genera texto como respuesta. Un agente ejecuta tareas, consulta sistemas externos, toma decisiones en múltiples pasos y completa flujos de trabajo de forma autónoma — todo dentro de los límites y permisos que la organización define. Ya lo vimos en acción con el agendamiento: el agente no le dijo al usuario “llámanos para coordinar una reunión.” Lo hizo él mismo, en tiempo real, conectándose a Google Calendar y cerrando el flujo completo sin intervención humana.
La evolución que visualizamos
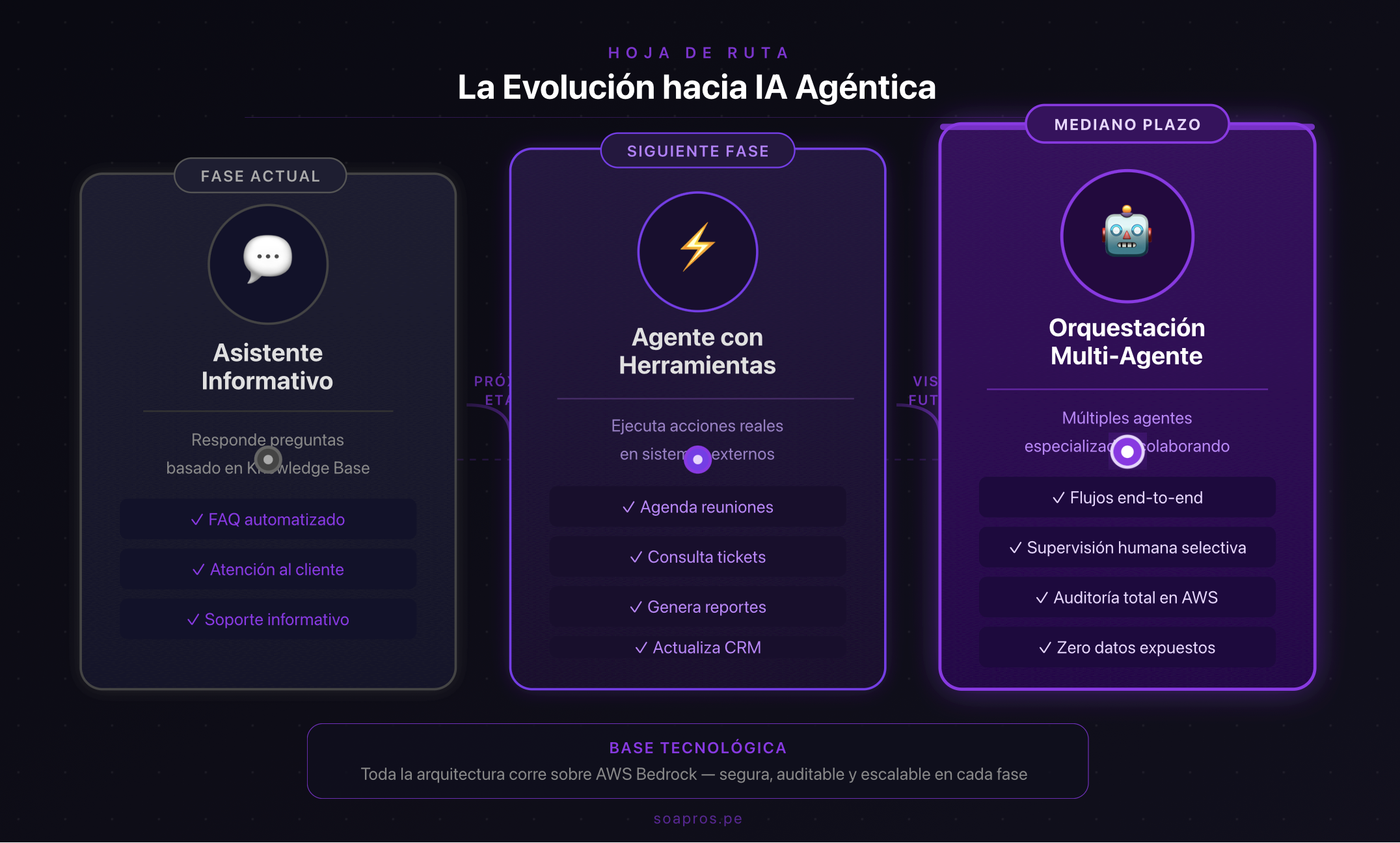
Las tres fases de madurez desde un asistente informativo hasta la orquestación multi-agente, todas sobre la misma base de AWS Bedrock.
Fase actual — Agente con herramientas: El agente ya responde preguntas basándose en la Knowledge Base y puede ejecutar acciones reales como agendar reuniones directamente en Google Calendar. Esta es la fase en la que SOAPros opera hoy.
Siguiente fase — Agente con más integraciones: El mismo agente expandiendo su alcance: consultar el estado de una propuesta, registrar un lead en el CRM, enviar un resumen de la conversación al equipo comercial, o notificar por Slack cuando un prospecto de alto valor inicia una conversación. Cada integración es una herramienta nueva que el agente puede usar de forma controlada y auditable.
Visión a mediano plazo — Orquestación multi-agente: Múltiples agentes especializados trabajando en conjunto. Un agente comercial que califica leads y agenda reuniones, un agente de onboarding que guía al cliente nuevo paso a paso, y un agente de soporte que resuelve dudas técnicas — todos coordinados, cada uno con acceso solo a lo que necesita, con trazabilidad completa en AWS.
¿Cómo se mantiene la seguridad en un esquema agéntico?
Esta es la pregunta correcta. Darle capacidad de acción a un agente de IA sin un modelo de seguridad sólido sería un error. La arquitectura sobre AWS Bedrock resuelve esto de forma nativa:
Principio de mínimo privilegio: Cada agente solo tiene acceso a las herramientas y datos estrictamente necesarios para su función. Un agente de soporte no puede acceder a datos financieros, aunque ambos corran sobre la misma plataforma.
Trazabilidad completa: Cada acción que ejecuta el agente queda registrada en CloudTrail. Quién lo activó, qué herramienta usó, qué datos consultó, qué resultado produjo. Auditable en cualquier momento.
Human-in-the-loop configurable: Para acciones de alto impacto —aprobar un presupuesto, modificar un registro crítico, enviar una comunicación externa— la arquitectura permite requerir confirmación humana antes de ejecutar. El agente propone, el humano aprueba.
Guardrails persistentes: Los filtros de contenido y comportamiento de Bedrock Guardrails se aplican a todos los agentes por igual, garantizando que ningún agente actúe fuera de los parámetros que la organización definió.
Lo que hoy hace nuestro agente con Google Calendar es exactamente el mismo patrón que mañana puede replicarse con cualquier sistema: un CRM, un ERP, una plataforma de pagos, o los sistemas internos de tu organización. La base está construida — escalar es cuestión de agregar herramientas, no de rehacer la arquitectura.
10. Recomendaciones para líderes técnicos y de negocio
Si estás evaluando cómo adoptar IA en tu organización, estos son los pasos que recomendamos desde SOAPros:
1. Antes de elegir la tecnología, mapea tus datos. ¿Qué tipos de información procesaría el modelo? ¿Hay datos regulados (salud, datos financieros, datos personales bajo GDPR o normas locales)? Esta evaluación define el nivel de control que necesitas.
2. Diferencia entre casos de uso de alto y bajo riesgo. No todos los usos de IA en tu empresa requieren el mismo nivel de protección. Empezar con casos de uso de bajo riesgo (redacción de comunicados, resumen de documentos públicos, FAQ interno) te permite aprender y construir confianza antes de abordar casos más sensibles.
3. Establece una política de uso de IA antes de lanzar herramientas. Qué herramientas están aprobadas, qué tipos de datos pueden usarse con cada una, qué está prohibido. Una página, clara, firmada por el equipo. Sin esto, el "shadow AI" —el uso no autorizado de herramientas de IA por parte de empleados— es inevitable.
4. No subestimes el TCO del on-premise. Si estás evaluando esta opción, incluye en el cálculo: hardware (inicial y de reposición cada 3–5 años), energía, personal técnico especializado, licencias de software de gestión, tiempo de integración y mantenimiento. Para la mayoría de las empresas en la región, el TCO del on-premise supera al cloud en un horizonte de 3 años.
5. Comunica la seguridad a equipos no técnicos con analogías claras. AWS Bedrock tiene más certificaciones de seguridad que la mayoría de los datacenters propios de las empresas de la región. Usar AWS no es "poner los datos en internet abierto" —es lo contrario. La misma confianza que depositamos en los bancos para guardar dinero sin necesidad de tener una bóveda propia en casa, aplica aquí.
6. Diseña pensando en agentes desde el inicio. Como demostramos con nuestro propio asistente, pasar de un chatbot informativo a un agente que ejecuta acciones reales — como agendar reuniones directamente en Google Calendar — no requiere rehacer la arquitectura si fue bien diseñada desde el principio. Cada capacidad agéntica nueva es simplemente una herramienta más que el agente puede usar. Cambiar la base tecnológica después es mucho más costoso que elegirla bien desde el inicio.
Conclusión: la pregunta no es si usar IA, sino cuándo empezar
Los modelos de lenguaje no van a desaparecer de la conversación empresarial. La pregunta ya no es si tu organización debería usarlos, sino cómo implementarlos de forma que generen valor sin comprometer la seguridad ni la privacidad de los datos.
La buena noticia es que esta es una pregunta que tiene respuesta técnica concreta. No requiere elegir entre “innovación” y “seguridad” — se pueden tener ambas con la arquitectura correcta, las políticas adecuadas y el socio tecnológico indicado. Y como demostramos con nuestra propia experiencia, el camino de AWS Bedrock permite llegar a producción rápido, con seguridad de nivel empresarial, y con una base que ya hoy soporta capacidades agénticas reales — no como promesa, sino como realidad en funcionamiento.
En SOAPros trabajamos precisamente en eso: ayudar a empresas a implementar soluciones de IA de forma segura, escalable y alineada con las necesidades reales de cada área de negocio. Ya sea sobre AWS Bedrock, con una arquitectura on-premise, o un esquema híbrido — primero entendemos tu organización, tus datos y tus restricciones, y desde ahí definimos la arquitectura correcta. Si no sabes por dónde empezar, también ofrecemos un Assessment de Arquitectura de IA: un análisis estructurado de tu situación actual, casos de uso prioritarios, nivel de sensibilidad de tus datos y recomendación concreta sobre qué modelo de despliegue tiene más sentido para ti — antes de invertir un solo dólar en infraestructura.
¿Tu organización está evaluando adoptar IA? Conversemos. (https://soapros.pe)
Glosario rápido
LLM (Large Language Model): Modelo de inteligencia artificial entrenado con grandes volúmenes de texto, capaz de entender y generar lenguaje natural. Ejemplos: Claude, GPT-4, Llama.
On-Premise: Infraestructura tecnológica instalada y operada en las propias instalaciones de la organización, sin depender de servicios de terceros en la nube.
AWS Bedrock: Servicio de Amazon Web Services que permite acceder y usar modelos de lenguaje de múltiples proveedores (Anthropic, Meta, Mistral, Amazon) dentro del entorno seguro de AWS.
RAG (Retrieval-Augmented Generation): Técnica que combina un modelo de lenguaje con una base de conocimiento propia de la empresa, para que el modelo responda basándose en documentos internos específicos.
Fine-tuning: Proceso de entrenar un modelo pre-existente con datos propios para especializarlo en tareas o dominios específicos. Diferente al uso normal del modelo vía API.
VPC (Virtual Private Cloud): Red privada virtual en AWS que aísla tus recursos y comunicaciones del resto del internet público.
KMS (Key Management Service): Servicio de AWS para crear y gestionar claves de cifrado que solo tu organización controla.
IAM (Identity and Access Management): Sistema de AWS para controlar quién tiene acceso a qué recursos y con qué permisos.
PII (Personally Identifiable Information): Cualquier dato que permita identificar a una persona: nombre, DNI, correo electrónico, número de teléfono, etc.
